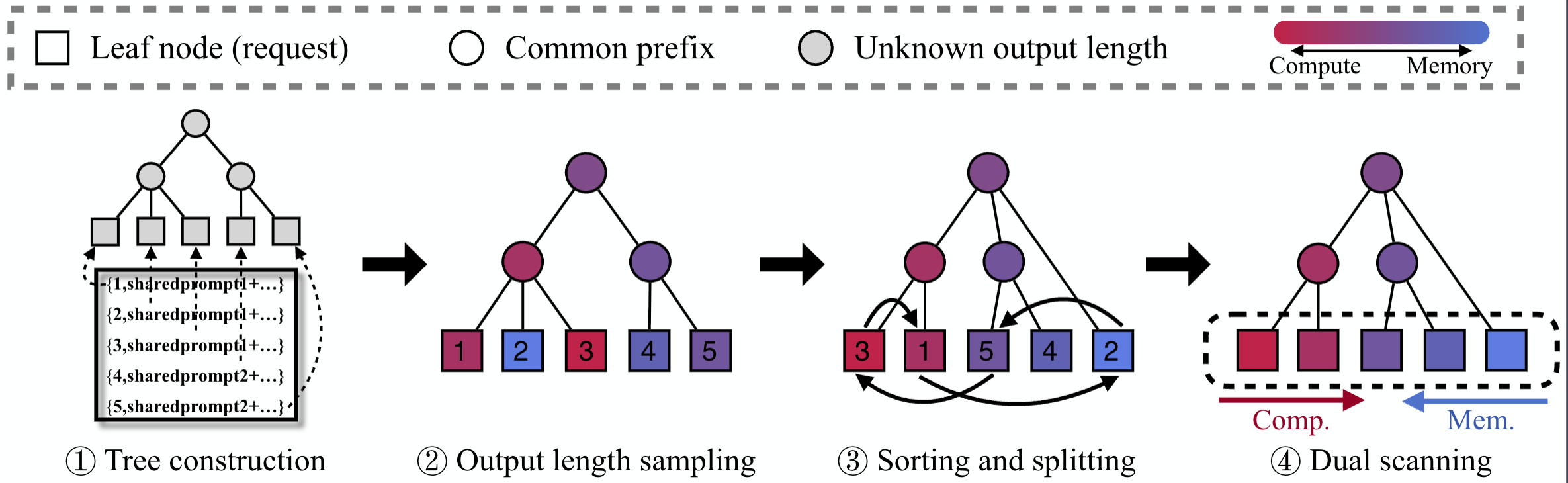
BlendServe studies offline inference for autoregressive large models, where latency requirements are relaxed but batch efficiency and resource utilization matter much more. The system reorders and overlaps requests with different resource demands while preserving prefix sharing.
This paper is part of my first-author publication set and is the most important LLM serving paper highlighted on the homepage.