Publications
Selected first-author publications are highlighted on the homepage. This page includes those papers together with additional collaborative work across LLM serving, sparse attention, and video generation.
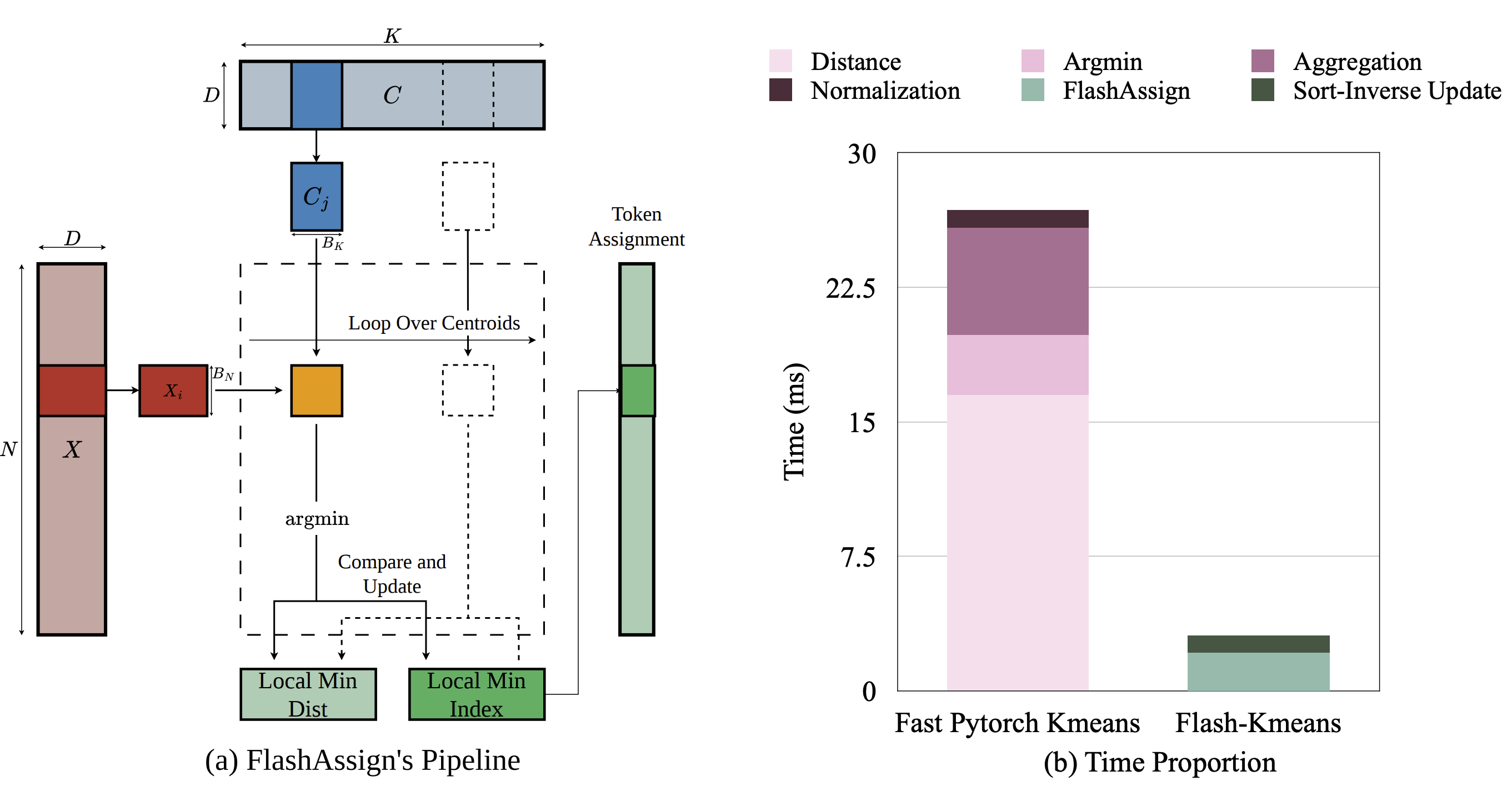
Exact K-Means
Kernel Optimization
Systems Primitive
Flash-KMeans
Fast and memory-efficient exact K-Means.
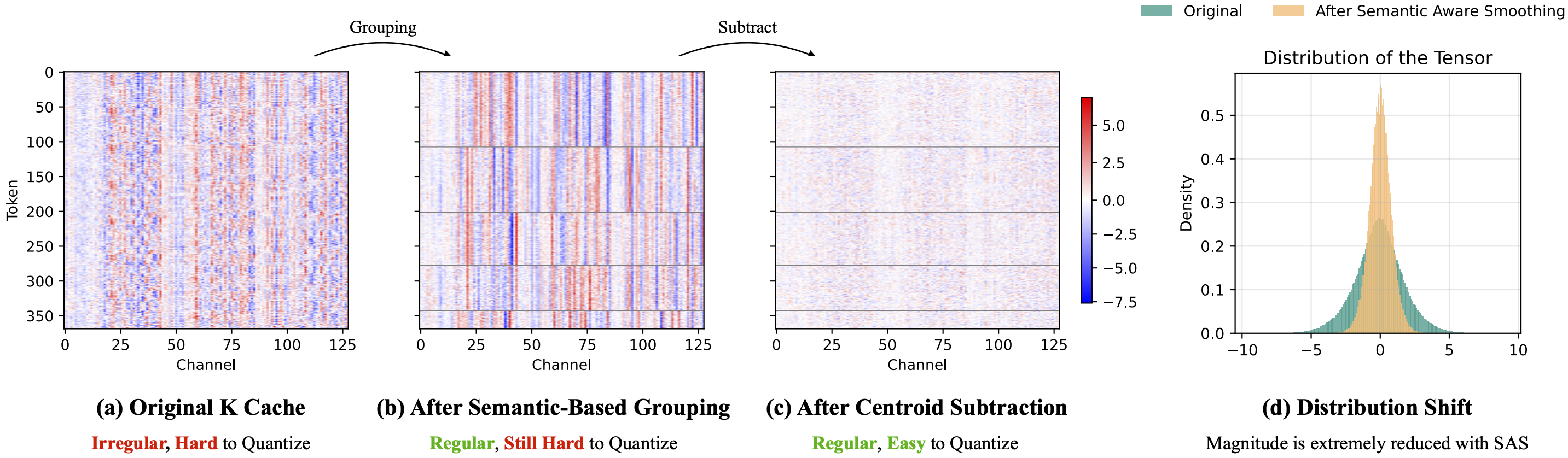
Long Video
KV Cache
Quantization
Quant VideoGen
Auto-regressive long video generation via 2-bit KV-cache quantization.
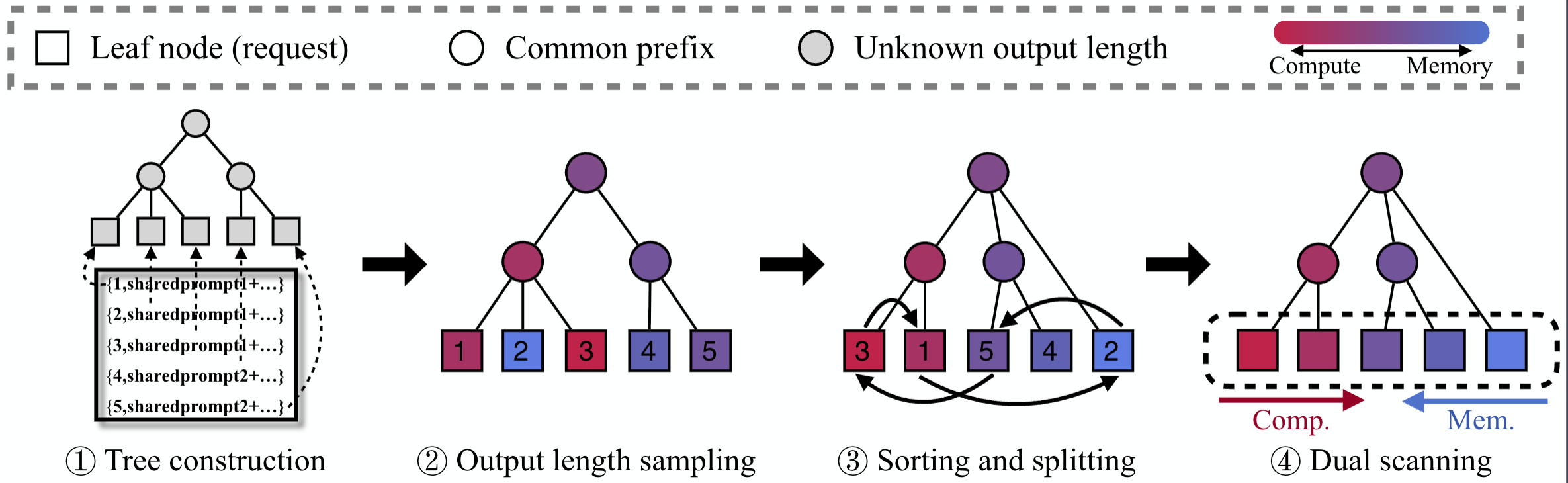
ASPLOS 2026
Offline Inference
LLM Serving
BlendServe
Optimizing offline inference for autoregressive large models with resource-aware batching.

MLSys 2026
Interactive Video
Streaming System
StreamDiffusionV2
A streaming system for dynamic and interactive video generation.

ICLR 2026
Verified Sparsity
Sparse Attention
vAttention
Verified sparse attention.
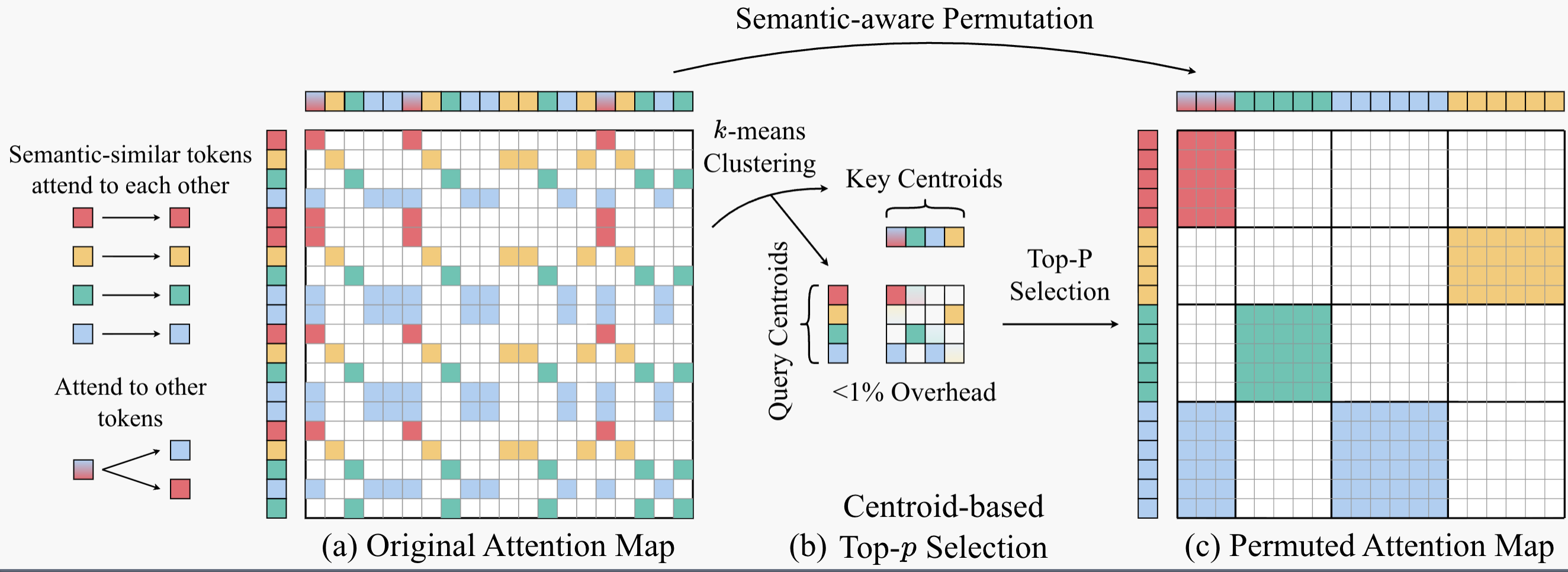
NeurIPS 2025 Spotlight
Semantic Permutation
Video Generation
Sparse VideoGen2
Accelerating video generation with sparse attention via semantic-aware permutation.

NeurIPS 2025
Long Video
Sparse Attention
Radial Attention
O(n log n) sparse attention with energy decay for long video generation.
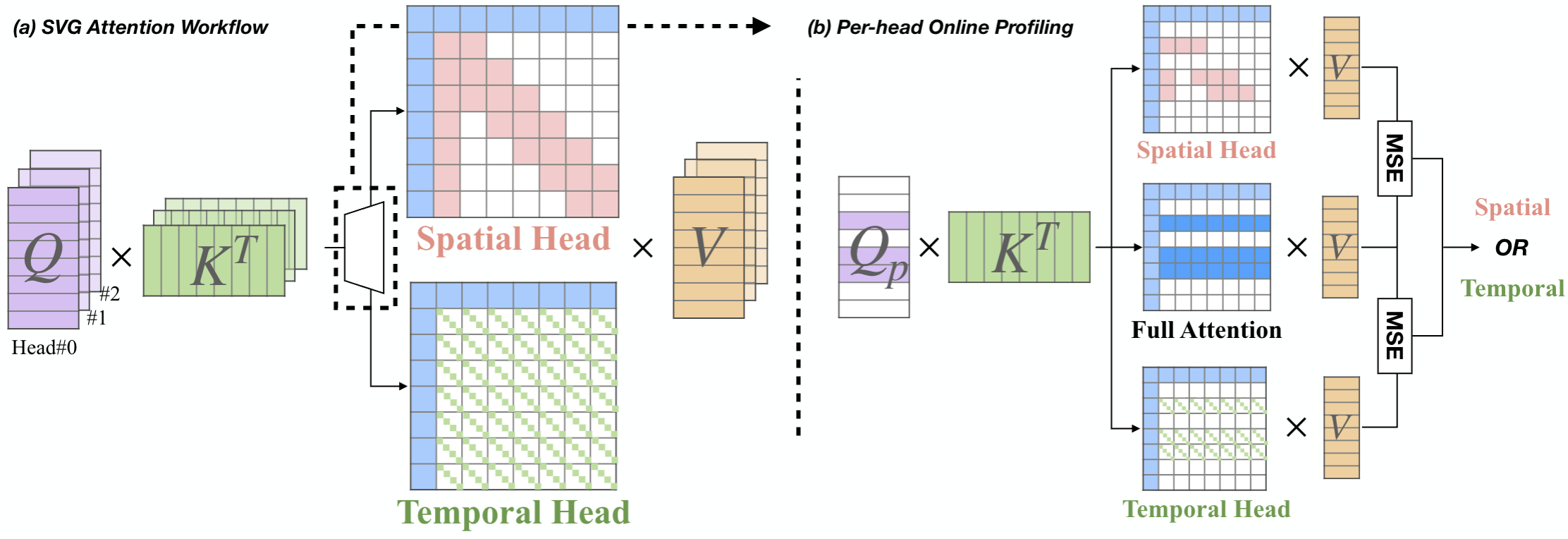
ICML 2025
Sparse Attention
Video Generation
Sparse VideoGen
Accelerating video diffusion transformers with spatial-temporal sparsity.
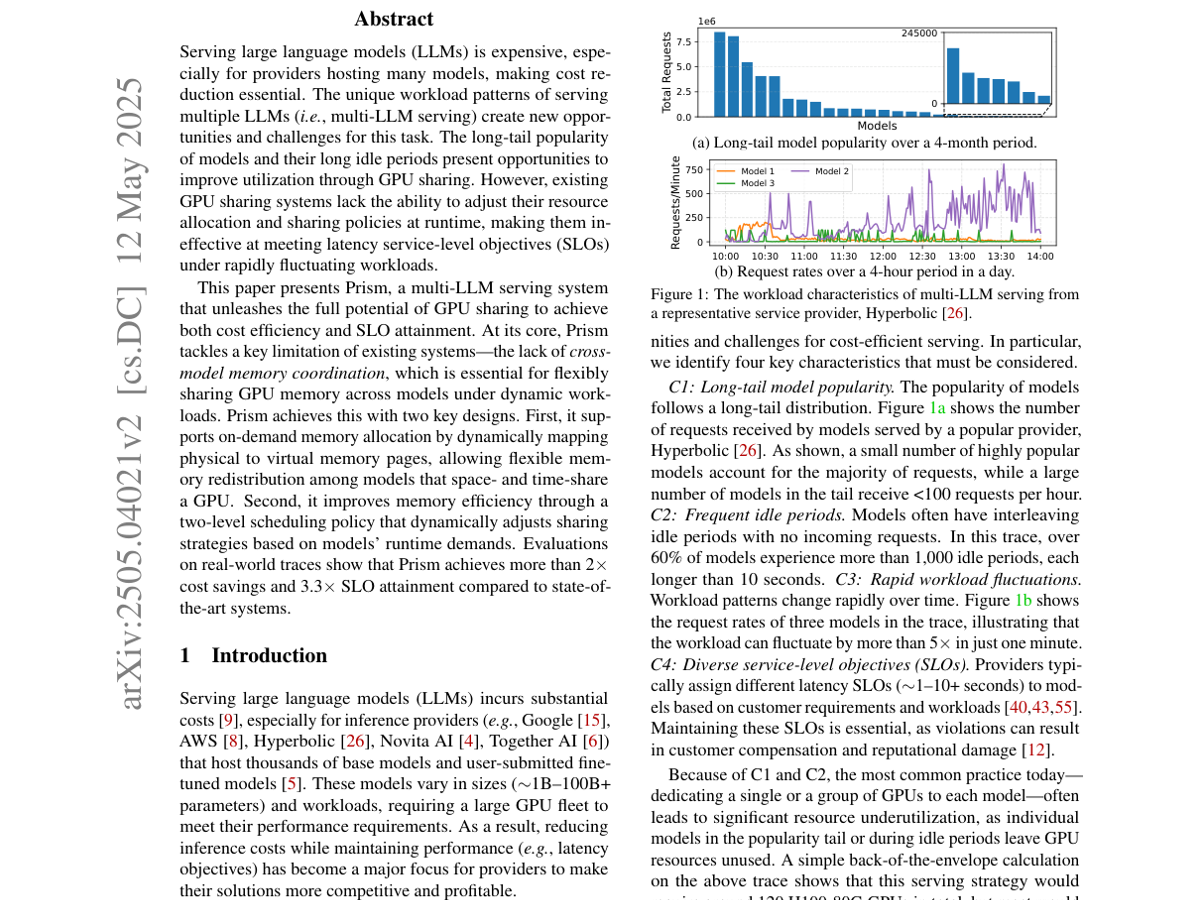
OSDI 2026
GPU Sharing
Multi-LLM Serving
Prism
Unleashing GPU sharing for cost-efficient multi-LLM serving.

NeurIPS 2025
Benchmark
World Models
WorldModelBench
Judging video generation models as world models.